CM3leon by Meta
Natural Language Processing
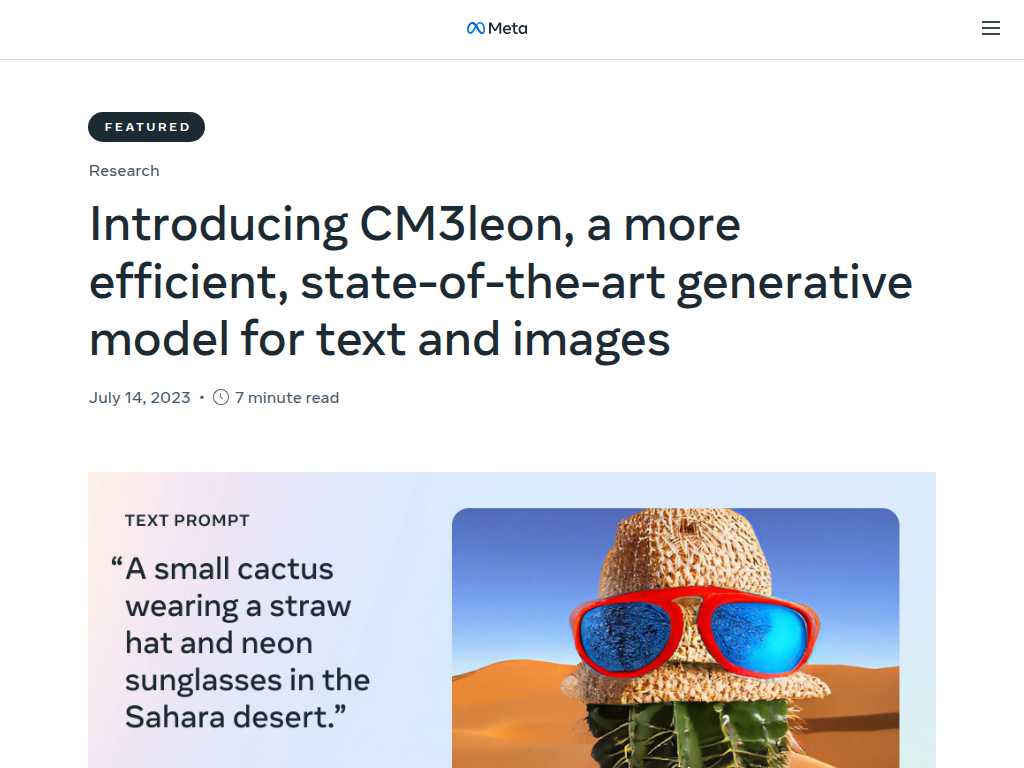
Discover CM3leon: The Versatile Multimodal AI for Text and Image Generation
Average rated: 0.00/5 with 0 ratings
Favorited 1 times
Rate this tool
About CM3leon by Meta
Create a 3 paragraph SEO optimized description for the product called CM3leon by Meta
Key Features
- Text-to-image generation
- Image-to-text generation
- Large-scale retrieval-augmented pre-training
- Multitask supervised fine-tuning
- High coherence and detail in generated images
- Low training costs and inference efficiency
- Versatile autoregressive model
- State-of-the-art performance
- Ability to handle complex compositional objects
- Efficient training methodology adapted from text-only models
Tags
multimodal modeltext-to-image generationimage-to-text generationMeta AIvision-language tasksimage caption generationvisual question answeringtext-based editing
FAQs
What is CM3leon?
CM3leon is a multimodal AI model capable of both text-to-image and image-to-text generation, developed by Meta AI.
What sets CM3leon apart from other models?
CM3leon uses a novel training methodology adapted from text-only language models, achieving state-of-the-art performance with less computational resources.
What are some key capabilities of CM3leon?
CM3leon excels in text-guided image generation, image caption generation, visual question answering, and text-based image editing.
How does CM3leon perform compared to other models?
CM3leon outperforms existing models like Google’s Parti in text-to-image generation benchmarks, setting a new state of the art with an FID score of 4.88.
What tasks can CM3leon handle?
CM3leon can handle tasks such as text-guided image generation and editing, visual question answering, and complex compositional object generation.
What is the training approach used for CM3leon?
CM3leon uses a large-scale retrieval-augmented pre-training stage followed by multitask supervised fine-tuning, adapted from text-only language models.
Is CM3leon efficient in terms of computational resources?
Yes, CM3leon achieves high performance despite being trained with five times less compute than previous transformer-based methods.
What makes CM3leon versatile?
CM3leon can generate sequences of text and images conditioned on arbitrary sequences of other image and text content, expanding its functionality beyond typical models.
What are some examples of CM3leon's text-to-image capabilities?
Examples include generating images of a small cactus wearing a straw hat, or a raccoon in an epic anime battle, based on detailed prompts.
What is the impact of CM3leon on future AI models?
CM3leon's innovative training approach and high performance with lower compute requirements pave the way for more efficient and versatile multimodal AI models in the future.